Creating Speech Zones with Self-distributing Acoustic Swarms
Malek Itani*, Tuochao Chen*, Takuya Yoshioka, Shyamnath Gollakota
(* Equal contribution)
University of Washington
Nature Communications, September 2023
Separating Five Speakers into Two Conversation Zones
Acoustic Swarms Overview
2D Localization of Moving Concurrent Speakers

A Seven-Robot Acoustic Swarm

Swarm Self-distributing Across a Table

Swarm Coming Back to the Base Station
Abstract
Imagine being in a crowded room with a cacophony of speakers and having the ability to focus on or remove speech from a specific 2D region. This would require understanding and manipulating an acoustic scene, isolating each speaker, and associating a 2D spatial context with each constituent speech. However, separating speech from a large number of concurrent speakers in a room into individual streams and identifying their precise 2D locations is challenging, even for the human brain. Here, we present the first acoustic swarm that demonstrates cooperative navigation with centimeter-resolution using sound, eliminating the need for cameras or external infrastructure. Our acoustic swarm forms a self-distributing wireless microphone array, which, along with our attention-based neural network framework, lets us separate and localize concurrent human speakers in the 2D space, enabling speech zones. Our evaluations showed that the acoustic swarm could localize and separate 3-5 concurrent speech sources in real-world unseen reverberant environments with median and 90-percentile 2D errors of 15 cm and 50 cm, respectively. Our system enables applications like mute zones (parts of the room where sounds are muted), active zones (regions where sounds are captured), multi-conversation separation and location-aware interaction.

Creating speech zones using the self-deployed microphone array. Once we localize and separate all speakers in the room, we can use the speakers' locations to manipulate every speaker's speech in the recorded audio. For example, we can create conversation zones and include all speech from inside these areas. Likewise, we can suppress sound coming from certain regions, creating mute zones.

An exploded view of a single robot. The dimensions of each robot is 30x26x30 mm.
Speech Extraction and Speaker Localization
We show some examples of our speaker localization and extraction pipeline on synthetic data and on real world data collected using our acoustic swarm.
Scenario 1 (3 speakers, real world recordings)
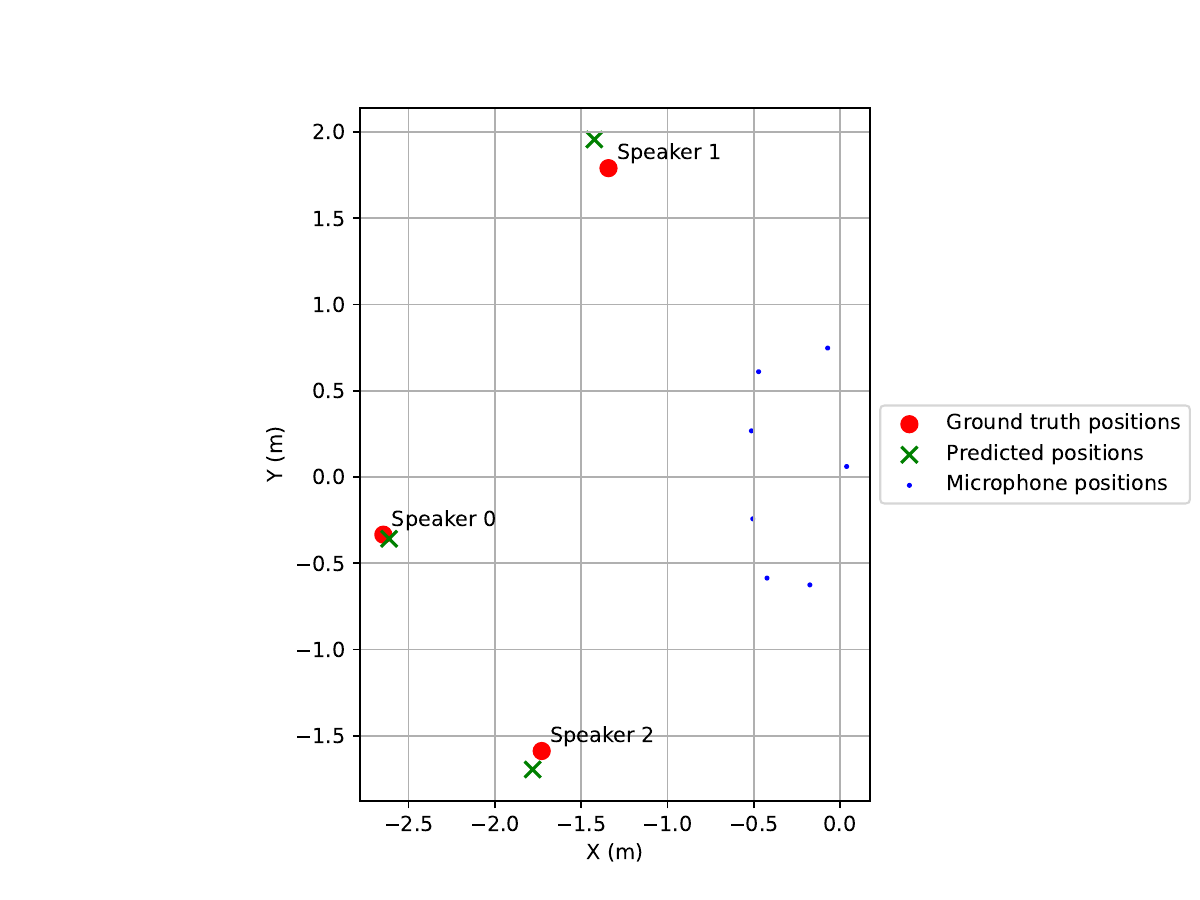
Input Mixture
| Speaker Number | Ground Truth | Ours | Ideal Binary Mask |
|---|---|---|---|
| Speaker 1 |
|
|
|
| Speaker 2 |
|
|
|
| Speaker 3 |
|
|
|
Scenario 2 (4 speakers, synthetically spatialized mixture)
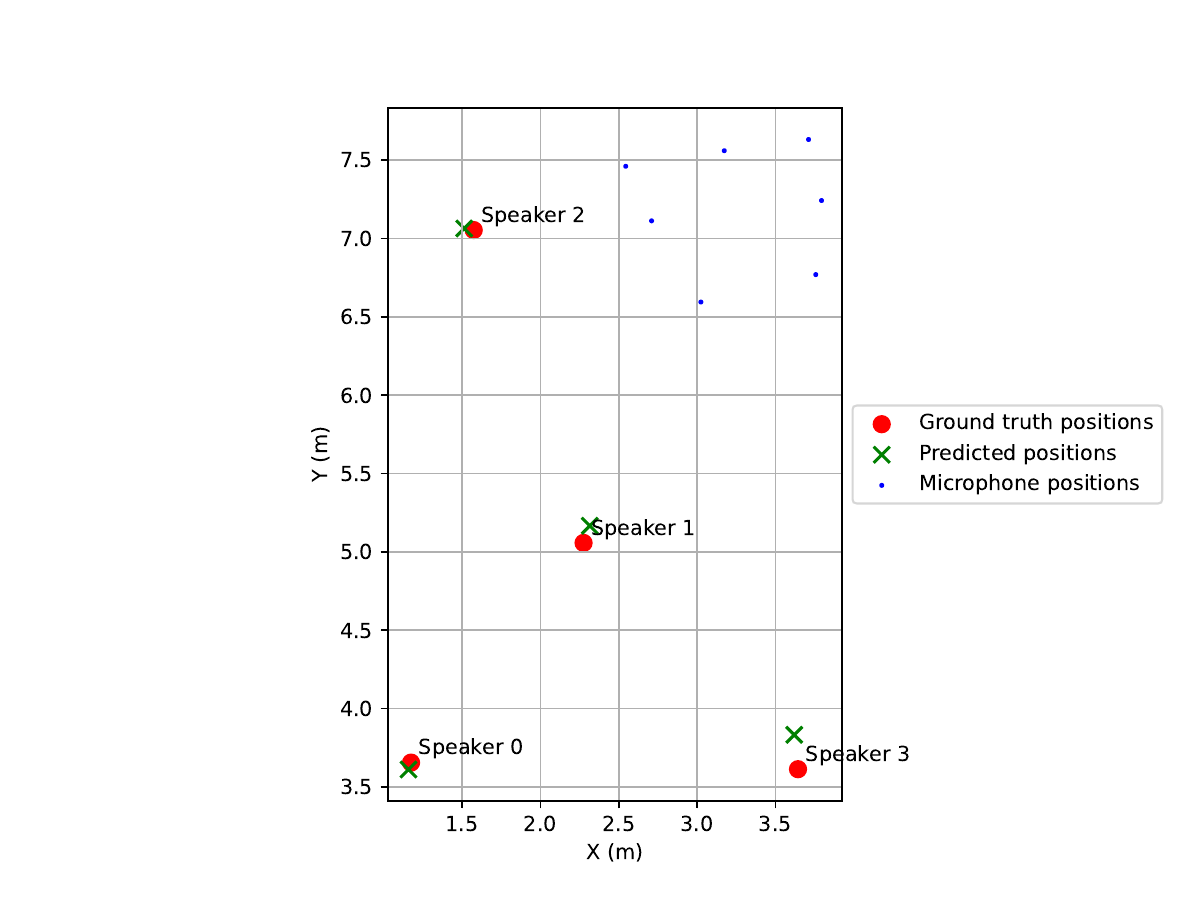
Input Mixture
| Speaker Number | Ground Truth | Ours | Ideal Binary Mask |
|---|---|---|---|
| Speaker 1 |
|
|
|
| Speaker 2 |
|
|
|
| Speaker 3 |
|
|
|
| Speaker 4 |
|
|
|
Scenario 3 (5 speakers, real world recordings)
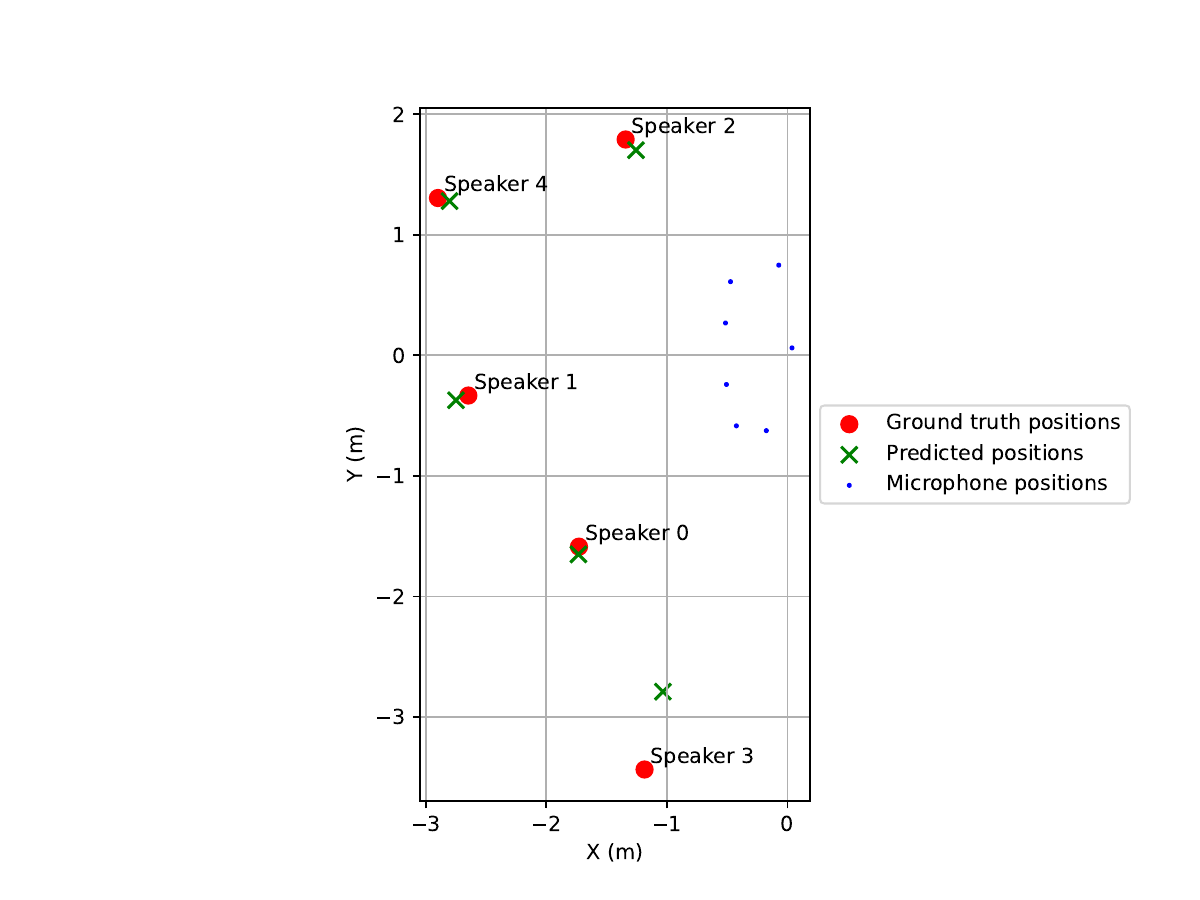
Input Mixture
| Speaker Number | Ground Truth | Ours | Ideal Binary Mask |
|---|---|---|---|
| Speaker 1 |
|
|
|
| Speaker 2 |
|
|
|
| Speaker 3 |
|
|
|
| Speaker 4 |
|
|
|
| Speaker 5 |
|
|
|
Keywords: Swarm robotics, acoustic localization, distributed microphone arrays, multichannel speech separation, speaker localization.
Contact: acousticswarm@cs.washington.edu